APEnet+ project
Project Background
Many scientific computations need multi-node parallelism for matching up both space (memory) and time (speed) ever-increasing requirements. The use of GPUs as accelerators introduces yet another level of complexity for the programmer and may potentially result in large overheads due to bookkeeping of memory buffers. Additionally, top-notch problems may easily employ more than a PetaFlops of sustained computing power, requiring thousands of GPUs orchestrated via some parallel programming model, mainly Message Passing Interface (MPI).
- Pictures of APEnet boards

APEnet+ board, front view

APEnet+ board, 3D Torus network cable connectors

APEnet+ 3 links test board, based on a commercial development board



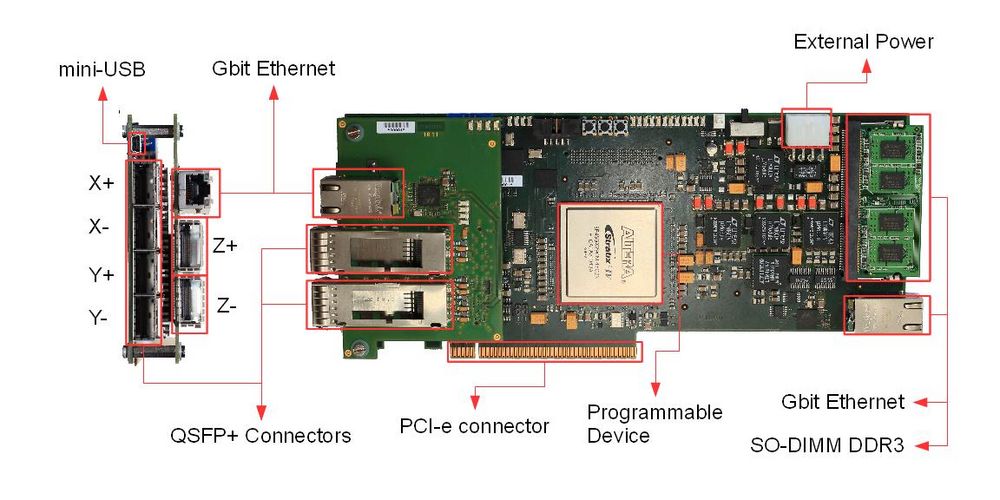
APEnet+ board technical details.

APEnet+ aim and features
The project target is the development of a low latency, high bandwidth direct network, supporting state-of-the-art wire speeds and PCIe X8 gen2 while improving the price/performance ratio on scaling the cluster size. The network interface provides hardware support for the RDMA programming model. A Linux kernel driver, a set of low-level RDMA APIs and an OpenMPI library driver are available; this allows for painless porting of standard applications.
Highlights
- APEnet+ is a packet-based direct network of point-to-point links with 2D/3D toroidal topology.
- Packets have a fixed size envelope (header+footer) and are auto-routed to their final destinations according to wormhole dimension-ordered static routing, with dead-lock avoidance.
- Error detection is implemented via CRC at packet level.
- Basic RDMA capabilities, e.g. RDMA PUT & SEND as well as address translation of memory registration, are implemented at the firmware level. RDMA GET is under development.
- Fault-tolerance features (will be added starting from 2012).
- Direct access to GPU memory using PCI express peer-to-peer (NVidia Fermi GPUs only).
GPU I/O accelerator
APEnet+ has the ability to take part in the so-called PCIe peer-to-peer (P2P)
transactions [[1]]; APEnet+ is the first non-NVIDIA device with specialized hardware blocks to support the NVIDIA GPUdirect peer-to-peer inter-GPU protocol. This means that the
APEnet+ network board can target GPU memory by ordinary RDMA semantics with no CPU
involvement and dispensing entirely with intermediate copies. In this way, real
zero-copy, inter-node GPU-to-host, host-to-GPU or GPU-to-GPU transfers can be achieved,
with substantial reductions in latency.
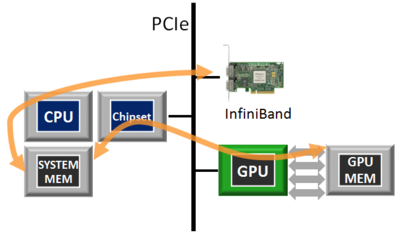
Traditional data flow: data transfers via off-the-shelf network interconnects (e.g. Infiniband) involve the CPU and necessitate of intermediate copies.
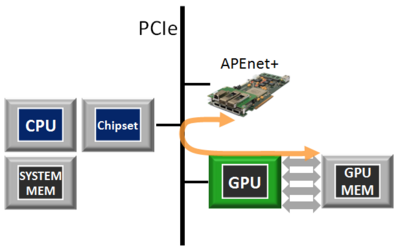
APEnet+ data flow: APEnet+ is the first non-NVIDIA device with specialized hardware blocks to support the NVIDIA GPUdirect peer-to-peer inter-GPU protocol, enabling zero-copy, inter-node GPU-to-host, host-to-GPU or GPU-to-GPU transfers with substantial reductions in latency.


PERFORMANCE
- APEnet+ bandwidth and latency
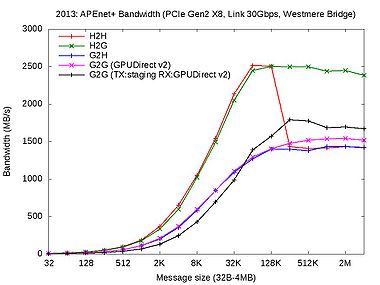
Bandwidth test
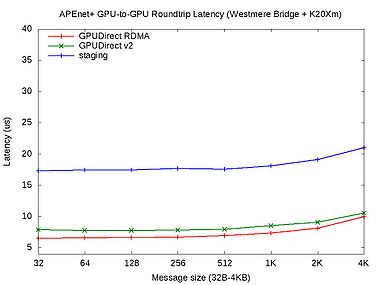
Roundtrip latency test


Acknowledgements
This work was partially supported by the EU Framework Programme 7 project EURETILE under grant number 247846. We would like to thank Massimiliano Fatica and Timothy Murray of NVIDIA Corp. for supporting the GPU P2P developments.
GPU Cluster installation
- Where: APE lab (INFN Roma 1)
- What: GPUcluster
APEnet+ Public Documentation
- APEnet+ flyer ← DOWNLOAD APEnet+ FLYER!!
- APEnet+ Photo Gallery
- APEnet+ Publications
Internal links (require login):
APEnet+ HW, APEnet+ SW, APEnet+ specification, Next Deadlines For Pubblication