Difference between revisions of "NaNet overview"
| Line 11: | Line 11: | ||
The RDMA feature combined with of a transport protocol layer offload module and a data stream processing stage makes NaNet a low-latency NIC suitable for '''real-time processing''' of data streams. | The RDMA feature combined with of a transport protocol layer offload module and a data stream processing stage makes NaNet a low-latency NIC suitable for '''real-time processing''' of data streams. | ||
| − | NaNet GPUDirect capability enables the connected processing system to exploit the high computing performances of modern '''GPUs on real-time applications'''. | + | NaNet GPUDirect capability enables the connected processing system to exploit the high computing performances of modern |
| + | '''GPUs on real-time applications'''. | ||
Since January 2015 NaNet is an [[image:Logo-infn.png|30px]][https://web2.infn.it/csn5/index.php/en/ INFN Scientific Committe 5] funded experiment. | Since January 2015 NaNet is an [[image:Logo-infn.png|30px]][https://web2.infn.it/csn5/index.php/en/ INFN Scientific Committe 5] funded experiment. | ||
Revision as of 12:15, 1 December 2015
NaNet is a FPGA-based PCIe Network Interface Card (NIC) design with Remote Direct Memory Access (RDMA) and GPUDirect P2P/RDMA capabilities featuring a configurable and extensible set of network channels.
The design supports both standard and custom channels:
- GbE (1000BASE-T)
- 10GbE (10Base-R)
- APElink (custom 34 Gbps link dedicated to HPC systems)
- KM3link (deterministic latency 2.5Gbps link used in the KM3Net-IT experiment data acquisition system)
The RDMA feature combined with of a transport protocol layer offload module and a data stream processing stage makes NaNet a low-latency NIC suitable for real-time processing of data streams.
NaNet GPUDirect capability enables the connected processing system to exploit the high computing performances of modern GPUs on real-time applications.
Since January 2015 NaNet is an ![]() INFN Scientific Committe 5 funded experiment.
INFN Scientific Committe 5 funded experiment.
NaNet Architecture
NaNet design is partitioned into 4 main modules: I/O Interface, Router, Network Interface and PCIe Core (see Fig.1).

- The I/O Interface module performs a \mbox{4-stages} processing on the data stream: following the OSI Model, the Physical Link Coding stage implements, as the name suggests, the channel physical layer (e.g., 1000BASE-T) while the Protocol Manager stage handles, depending on the kind of channel, data/networ/transport layers (e.g., UDP or Time Division Multiplexing Protocol); the Data Processing stage implements application-dependent processing on data streams (e.g., performing de/compression) while the APEnet Protocol Encoder performs protocol adaptation, encapsulating inbound payload data in the APElink packet protocol --- used in the inner NaNet logic --- and decapsulating outbound APElink packets before re-encapsulating their payload into output channel transport protocol (e.g., UDP).
- The Router module supports a configurable number of ports implementing a full crossbar switch responsible for data routing and dispatch. Number and bit-width of the switch ports and the routing algorithm can all be defined by the user to automatically achieve a desired configuration. The Router block dynamically interconnects the ports and comprises a fully connected switch, plus routing and arbitration blocks managing multiple data flows @2.8 GB/s.
- The Network Interface block acts on the trasmitting side by gathering data incoming from the PCIe port and forwarding them to the Router destination ports; on the receiving side it provides support for RDMA in communications involving both the host and the GPU (via a dedicated GPU I/O Accelerator module). A NIOS-II microcontroller handles configuration and runtime operations.
- The PCIe Core module is built upon a powerful commercial core from PLDA that sports a simplified but efficient backend interface and multiple DMA engines.
This general architecture has been specialized up to now into three configurations, namely NaNet-1, NaNet3 and NaNet-10, to match the requirements of different experimental setups:
- NaNet-1 featuring a PCIe Gen2 x8 host interface plus a GbE one, three optional 34 Gbps APElink channels and is implemented on the Altera Stratix IV FPGA Development Kit.
- NaNet3 implemented on the Terasic DE5-NET Stratix V FPGA development board sporting four SFP+ cages. It supports four 2.5~Gbps deterministic latency optical KM3link channels and a PCIe Gen2 x8 host interface.
- NaNet-10 featuring four 10GbE SFP+ ports along with a PCIe Gen2 x8 host interface and also implemented on the Terasic DE5-NET board.
The board is able to manage either 34 Gbps APElink channel or 1/10 GbE interfaces and exploit the GPUDirect P2P capabilities of NVIDIA Fermi/Kepler GPUs equipping a hosting PC to directly inject into their memory an UDP input data stream from the detector front-end, with rates compatible with the low latency real-time requirements of the trigger system.
In order to render harmless the unavoidable OS jitter effects that usually hinder system response time stability, the main design rule is to partition the system so that the hosting PC CPU can be offloaded from any data communication or computing task, leaving to it only system configuration and GPU kernel launch tasks. Within NaNet, this meant that data communication tasks were entirely offloaded to a dedicated UDP protocol-handling block directly communicating with the P2P logic: this allows a direct (no data coalescing or staging is performed) data transfer with low and predictable latency on the GbE link → GPU data path.
The UDP OFFLOAD block comes from an open core module [1] built for a Stratix II 2SGX90 development board. Focus of that design is the unburdening of the Nios II soft-core microprocessor onboard the Stratix II from UDP packet management duties by a module that collects data coming from the Avalon Streaming Interface (Avalon-ST) of the Altera Triple-Speed Ethernet Megacore (TSE MAC) and redirects UDP packets along a hardware processing data path. The Nios II subsystem executes the InterNiche TCP/IP stack to setup and tear down UDP packet streams which are processed in hardware at the maximum data rate achievable over the GbE network.
Bringing the open core into the NaNet design required some modifications, first of all the hardware code was upgraded to work on the Stratix IV FPGA family; this upgrade made available the improved performances of an FPGA which is two technology steps ahead in respect to the Stratix II.
The synthesis performed on a Stratix IV achieves the target frequency of 200 MHz (in the current APEnet+ implementation, the Nios II subsystem operates at the same frequency). Current NaNet implementation provides a single 32-bits wide channel; it achieves 6.4 Gbps at the present operating frequency, 6 times greater than what is required for a GbE channel. Data coming from the single channel of the modified UDP OFFLOAD are collected by the NaNet CTRL. NaNet CTRL is a hardware module in charge of managing the GbE flow by encapsulating packets in the typical APEnet+ protocol (header, footer and a payload whose maximum size is 4096 bytes).
Incoming data streams are processed by a Physical Link Coding block feeding the Data Protocol Manager that in turn extracts the payload data. These payload data are encapsulated by the NaNet Controller and sent to the APEnet+ Network Interface.
The Distributed Network Processor (DNP)[2] is the APEnet+ core logic, acting as an off-loading engine for the computing node in performing inter-node communications. The DNP provides hardware support for the Remote Direct Memory Access (RDMA) protocol guaranteeing low-latency data transfers. Moreover, APEnet+ is also able to directly access the Fermi- and Kepler-class NVIDIA GPUs memory (provided that both devices share the same upstream PCIe root complex) leveraging their peer-to-peer capabilites. This is a first-of-its-kind feature for a non-NVIDIA device (GPUDirect RDMA being its commercial name), allowing unstaged off-board GPU-to-GPU transfers with unprecedented low latency.
NaNet Architecture and Data Flow
- APEnet+ Firmware Customization.
- UDP offload collects data coming from the Altera Triple-Speed Ethernet Megacore (TSE MAC) and extracts UDP packets payload, providing a 32-bit wide channel achieving 6.4~Gbps, discharging the Nios II from the data protocol management.
- NaNet Controller (CTRL) encapsulates the UDP payload in a newly forged APEnet+ packet, sending it to the RX Network Interface logic.
- RX DMA CTRL manages CPU/GPU memory write process, providing hw support for the Remote Direct Memory Access (RDMA) protocol.
- Nios II handles all the details pertaining to buffers registered by the application to implement a zero-copy approach of the RDMA protocol (OUT of the data stream).
- EQ DMA CTRL generates a DMA write transfer to communicate the completion of the CPU/GPU memory write process.
- A Performance Counter is used to analyze the latency of the GbE data flow inside the NIC.
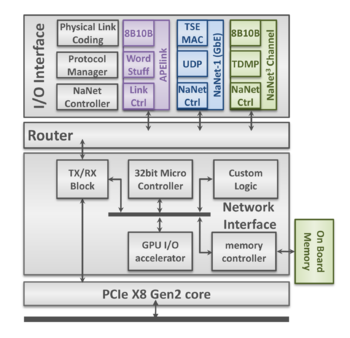
Figure 1. NaNet Architecture and Data Flow.

Figure 2. NaNet-1 implemented on an Altera Stratix IV coupled with a custom mezzanine card sporting 3 APE link channels.


NaNet-1
This version of the NIC features GPUDirect RDMA over 1 GbE and optionally 3 APElink channels. The design employs SGMII standard interface to connect the MAC to the PHY including Management Data I/O (MDIO); the MAC is a single module in FIFO mode for both the receive and the transmit sides (2048x32 bits). The logic resources consumption is shown in fig. 1.
Software Stack
Software components for NaNet-1 operation are needed both on the x86 host and on the Nios II FPGA-embedded μcontroller. On the x86 host, a GNU/Linux kernel driver and an application library are present. The application library provides an API mainly for open/close device operations, registration (i.e. allocation, pinning and returning of virtual addresses of buffers to the application) and deregistration of circular lists of persistent receiving buffers (CLOPs) in GPU and/or host memory and signalling of receive events on these registered buffers to the application (e.g. to invoke a GPU kernel to process data just received in GPU memory, see fig. 4). On the μcontroller, a single process application is in charge of device configuration, generation of the destination virtual address inside the CLOP for incoming packets payload and virtual to physical memory address translation performed before the PCIe DMA transaction to the destination buffer takes place.
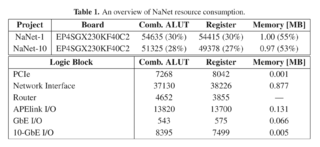
Figure 3. NaNet_1_10_Resource_Consumption.png.
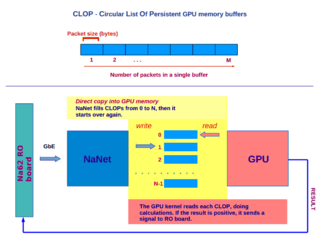
Figure 4. CLOPs scheme and their implementation in the NA62-NaNet-GPU work flow.
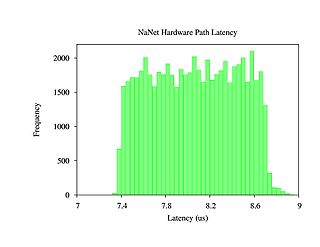
Figure 5. Distribution plot over 60000 samples of a NaNet trasversal time.
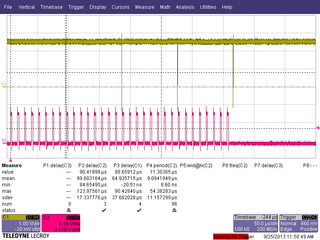
Figure 6. TEL62 to NaNet communication latency measurements performed with an oscilloscope.




NIC packets traversal latency
In order to characterize the host+NIC system, a “system loopback” configuration was used: connecting one GbE interface of the hosting PC to the NaNet, it was possible able to generate and receive a UDP stream in a single host process, measuring latency as the difference of host processor Time Stamp Counter register at send and receive time of the same UDP packet. Latency inside the NIC was measured adding 4 cycles counters at different stages of packet processing; their values are stored in a profiling packet footer with a resolution of 4 ns; for a standard 1472 bytes UDP packet, traversal time ranges between 7.3 us and 8.6 us from input of NaNet CTRL to the completion signal of the DMA transaction on the PCIe bus (fig. 5). For the same packet size, saturation of the GbE channel is achieved, with 119.7 MB of sustained bandwidth. For scheduled improvements on the NaNet design see NaNet-10.
A physics case: the Low Level trigger in NA62 Experiment's RICH Detector
NaNet is currently being used in a pilot project within the CERN NA62 experiment aiming at investigating GPUs usage in the central Level 0 trigger processor (L0TP) [3]. Data communication between the TEL62 readout boards and the L0 trigger processor (L0TP) happens over multiple GbE links using UDP streams. The main requisite for the communication system comes from the request for <1 ms and deterministic response latency of the L0TP: communication latency and its fluctuations are to be kept under control.
The board integration in a working environment has been tested connecting a TEL62 to NaNet Gbe port and sending some Monte Carlo-generated events. An example of latency measurements performed with an oscilloscope is shown in fig. 6: a bunch of 32 UDP packets is sent from TEL62 (red signal), thereby 4 PCIe completions (yellow signal) pinpoint the end of the DMA write transactions towards the GPU memory buffers, each sized 8 times the udp packet payload size.
Performance Analysis
To carry on such measures, "loopback" setups were used. That is
- one of the host GbE ports sending UDP packets (according to the NA62 RICH readout data protocol) to the NaNet-1 GbE interface;
- connecting two of the three available APElink ports to perform the same measurement.
In this way, being the x86 TSC register a common reference time, it was possible to measure in a single process test application:
- latency as time difference between when a received buffer is signalled to the application and the moment before the first UDP packet of a bunch (needed to fill the receive buffer) is sent through the host GbE port;
- time spent by GPU kernel on ring reconstruction.
Bandwidth and latencies benchmarks results are shown for both GbE and APElink in figures 7,8,9,10.
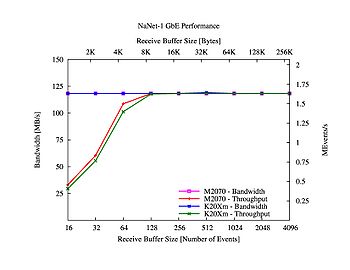
Figure 7. NaNet-1 GbE bandwidth and throughput.
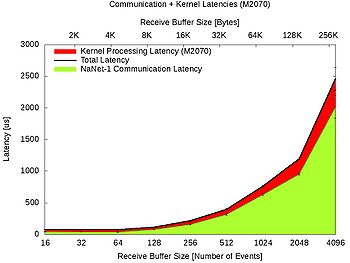
Figure 8. NaNet-1 GbE data transfer and CUDA kernel ring reconstruction.


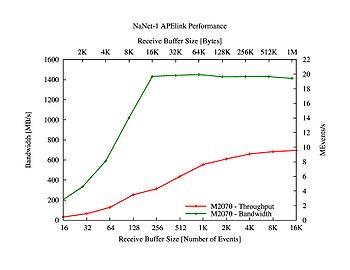
Figure 9. NaNet-1 APElink bandiwdth and throughput
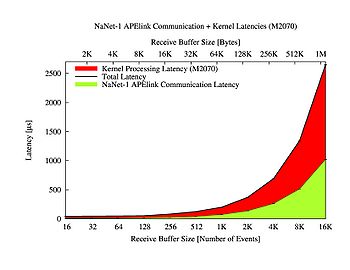
Figure 10. NaNet-1 APElink data transfer and CUDA kernel ring reconstruction.


- Note
- Communication and kernel processing tasks were serialized in order to perform the measure. This represents a worst-case situation: during normal operation given NaNet-1 RDMA capabilities, this serialization does not happen, and kernel processing seamlessly overlaps with data transfer. This is confirmed by throughput measurements in figure 5. Combining the results, it is clear that the system remains within the 1 ms time budget with GPU receive buffer sizes in the 128-1024 events range while keeping a ~ 1:7 MEvents/s throughput. Although real system physical link and data protocol were used to show the real-time behaviour on NaNet-1, we measured on a reduced bandwidth single GbE port system that could not match the 10 MEvents/s experiment requirement for the L0TP.
- To demonstrate the suitability of NaNet-1 design for the full-fledged RICH L0TP, equivalent benchmarks were performed using one of its APElink ports instead of the GbE one. Results for throughput and latency of the APElink-fed RICH L0TP are shown in figure 7 and 8: a single NaNet-1 APElink data channel between RICH RO and GRL0TP systems roughly matches trigger throughput and latency requirements for receiving buffer size in the 4~5 Kevents range.
Further enhancements and NaNet-10
As described above, the NaNet GPU memory addressing is managed by the Nios II firmware. Implementing new features with a μcontroller is a fast and efficient strategy during debugging phase but the Nios II introduces a considerable latency in performing the basic RDMA tasks: buffer search and translation of virtual addresses to physical ones. Moreover, it is responsible of jitter effects on the hardware latency path [4]. Thus, two major improvements are currently under development for NaNet-1: a Translation Lookaside Buffer (TLB), an associative cache where a limited amount of entries can be stored in order to perform memory management tasks, taking only ~200 ns and a hardware module for virtual address generation for GPU memory management. The expected request of increased data rates and considerations of future-proofing for the NaNet IP pushed the design of a board supporting the more advanced 10-GbE industrial through an additional board from Terasic (Dual XAUI To SFP+ HSMC).
NaNet3

{kind=link}
To be complete, an overview of the NaNet board family must mention the undergoing development of the NaNet3 board for the KM3 HEP experiment[5]. In KM3 the board is tasked with delivering global clock and synchronization signals to the underwater electronic system and receiving photomultipliers data via optical cables. The design employs Altera Deterministic Latency Transceivers with an 8B10B encoding scheme as Physical Link Coding and Time Division MultiPlexing (TDMP) data transmission protocol. Current implementation is being developed on the Altera Stratix V development board with a Terasic SFP-HSMC daughtercard plugged on top and sporting 4 transceiver-based SFP ports.
NaNet Public Documentation
References
- ↑ http://www.alterawiki.com/wiki/Nios_II_UDP_Offload_Example
- ↑ A. Biagioni, F. Lo Cicero, A. Lonardo, P.S. Paolucci, M. Perra, D. Rossetti, C. Sidore, F. Simula, L. Tosoratto and P. Vicini - The Distributed Network Processor: a novel off-chip and on-chip interconnection network architecture, March 2012. (http://arxiv.org/abs/1203.1536).
- ↑ G. Lamanna, G. Collazuol, Marco Sozzi - GPUs for fast triggering and pattern matching at the CERN experiment NA62, Nuclear Science Symposium Conference Record, 2009
- ↑ R. Ammendola, A. Biagioni, R. Fantechi, O. Frezza, G. Lamanna, F. Lo Cicero, A. Lonardo, F. Pantaleo, R. Piandani, L. Pontisso, D. Rossetti, F. Simula, L. Tosoratto, P. Vicini - NaNet: a low-latency NIC enabling GPU-based, real-time low level trigger systems, International Conference on Computing in High Energy and Nuclear Physics (CHEP), October 2013, Amsterdam, Netherland. (http://arxiv.org/abs/1311.1010). To be published.
- ↑ M. Ageron e al., Technical Design Report for a Deep-Sea Research Infrastructure in the Mediterranean Sea Incorporating a Very Large Volume Neutrino Telescope, Tech. Rep. ISBN 978-90-6488-033-9.