Abstract Processing Environment for Intelligent Read-Out systems based on Neural networks
APEIRON is a framework consisting of a generic architecture of a distributed computing platform and its complete software stack, from device driver to high level programming model. The framework has been conceived to prototype and deploy intelligent systems in the Trigger and Data Acquisition (TDAQ) context of High Energy Physics (HEP) experiments. It leverages a high degree of abstraction, modern electronic technology and modern coding approach to efficiently develop solutions that implements neural networks in a lower–level trigger module of traditional setups or in a data reduction stage in triggerless systems.
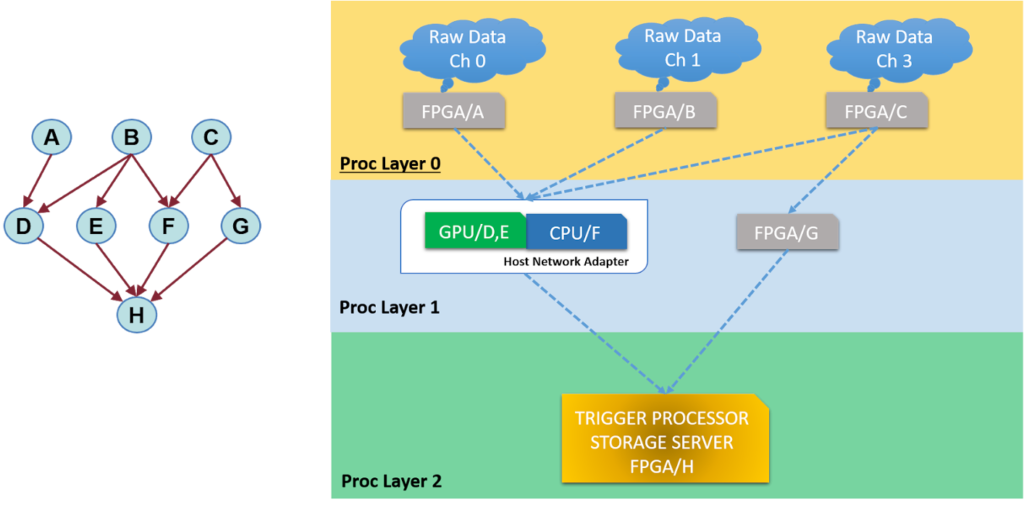
An APEIRON architecture is made of several input data channels that in TDAQ for HEP correspond to detectors and subdetector modules. Input channels are connected to several multi-processors streaming layers with the output layer being a trigger processor or a storage server depending on the application. The platform is modular, scalable and has a configurable topology as its strong points. The configurable topology allows for arbitrary combinations of data to flow through the computational network across the different processing layers. The latter can be any sets of heterogeneous devices, namely FPGA, CPU and GPU, conveniently defined at early stage of design to take advantage of the peculiar hardware characteristics of each one in terms of timing, memory and computing power.
Hardware abstraction and optimal application mapping are based on two key elements:
-
A distributed dataflow programming model based on Kahn Process Networks (KPN)
-
The adoption of modern High Level Synthesis design tools for FPGA.
Thus, a computation can be represented as a direct graph in which the vertices are computational tasks to be executed on platform nodes and the oriented edges are communication channels for data streaming between tasks. Using high-level language (C/C++) implies code portability and an adequate level of abstraction from the actual device that is going to implement a task. In addition, direct graphs representation let the application to be simulated in advance so that the optimal partitioning can be defined even before the hardware is practically available. Another byproduct of this approach is that different mappings for a single application can be simulated speeding up the prototyping phase.
APEIRON framework is flexible and can be used in the new experimental scenarios characterized by elevated particle rates and huge number of channels. In the case of triggered systems, we aim at developing and deploying innovative algorithms based on deep and spiking neural networks to improve trigger efficiency in online systems. In fact, the architecture and the programming model are conceived to support the distributed implementation of machine learning calculations by mapping different layers and subnets on interconnected processing elements. A first use case of APEIRON is a FPGA based neural network for implementing partial particle identification in the low-level trigger of NA62 experiment at CERN. In a second case we’re going to use APEIRON framework in a streaming readout system for the online data reduction and permanent storage of the data frames.