Leveraging the acquired know-how in networking and re-employing the gained insights, a spin-off project called APEnet developed an interconnect board based on FPGA that allows to assemble a PC cluster a la APE with off-the-shelf components.
The design of APEnet interconnect is easily portable and can be configured for different environments: (i) the APEnet was the first point-to-point, low-latency, high-throughput network interface card for LQCD dedicated clusters; (ii) the Distributed Network Processor (DNP) was one of the key elements of RDT (Risc+DSP+DNP) chip for the implementation of a tiled architecture in the framework of the EU FP6 SHAPES project; (iii) the APEnet Network Interface Card, based on an Altera Stratix IV FPGA, was used in a hybrid, GPU-accelerated x86 64 cluster QUonG with a 3D toroidal mesh topology, able to scale up to 10^4 – 10^5 nodes in the framework of the EU FP7 EURETILE project. APEnet+ was the first device to directly access the memory of the NVIDIA GPU providing GPUDirect RDMA capabilities and experiencing a boost in GPU to GPU latency test; (iv) the APEnet network IP — i.e. routing logic and link controller — is responsible for data transmision at Tier 0/1/2 in the framework of H2020 ExaNeSt project
| Year | |||||
| FPGA | |||||
| BUS | |||||
| Computing | |||||
| Bandwidth | |||||
| Latency |
APEnet Interconnect Architecture based on a layer models
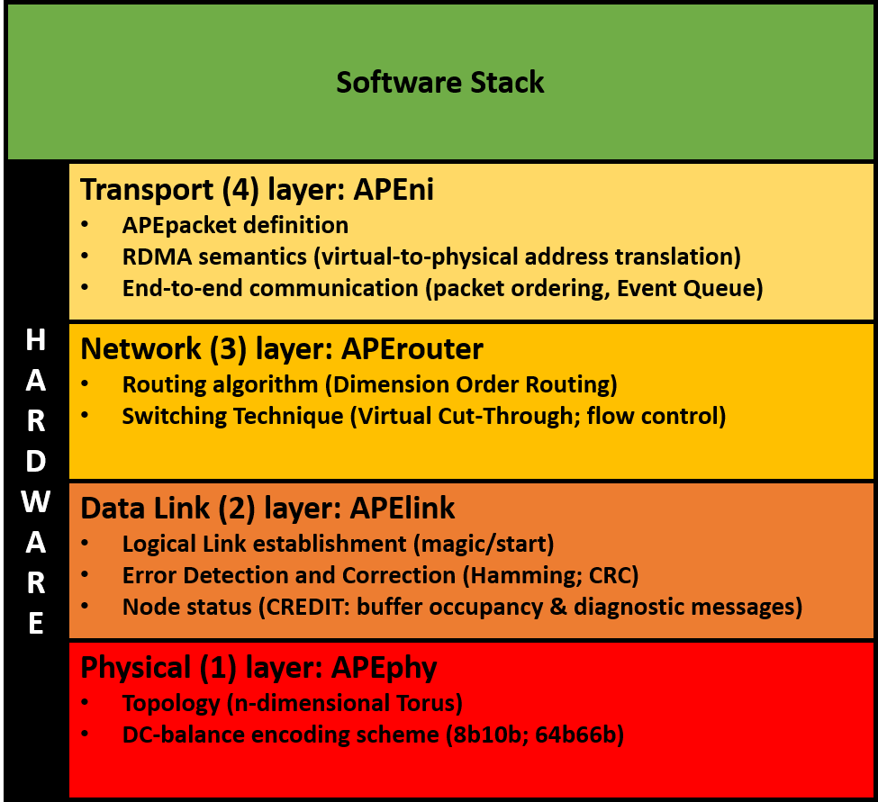
The physical layer defines the data encoding scheme for the serialization of the messages over the cable and shapes the network topology. APEphy provides point-to-point bidirectional, full-duplex communication channels of each node with its neighbours along the available directions (i.e. the connectors composing the IO interface). APEphy is normally based on a customization of tools provided by the FPGA vendor —i.e. DC-balance encoding scheme, deskewing, alignment mechanism, byte ordering, equalization, channel bonding.
The data-link layer establishes the logical link between nodes and guarantees reliable communication, performing error detections and corrections. APElink is the INFN proprietary high-throughput, low-latency data transmission protocol for direct network interconnect based on word-stuffing technique, meaning that the data transmission needs submission of a magic word every time a control frame is dispatched to distinguish it from data frames. The APElink manages the frame flow by encapsulating the packets into a light, low-level protocol. Further, it manages the flow of control messages for the upper layers describing the status of the node and transmitted through the APElink protocol.
The network layer defines the switching technique and routing algorithm. The Routing and Arbitration Logic manages dynamic links between blocks connected to the switch. The APErouter applies a dimension order routing policy: it consists in reducing to zero the offset between current and destination node coordinates along one dimension before considering the offset in the next dimension. The employed switching technique— i.e. when and how messages are transferred along the paths established by the routing algorithm, de facto managing the data flow — is Virtual Cut-Through : the router starts forwarding the packet as soon as the algorithm has picked a direction and the buffer used to store the packet has enough space.
The transport layer defines end-to-end protocols and the APEpacket. The APE Network Interface block has basically two main tasks: on the transmit data path, it gathers data coming in from the bus interfacing the programming subsystem, fragmenting the data stream into packets — APEpacket— which are forwarded to the relevant destination ports, depending on the requested operation; on the receive side, it implements PUT and GET semantics providing hardware support for the RDMA (Remote Direct Memory Access) protocol that allows to transfer data over the network without explicit support from the remote node’s CPU.
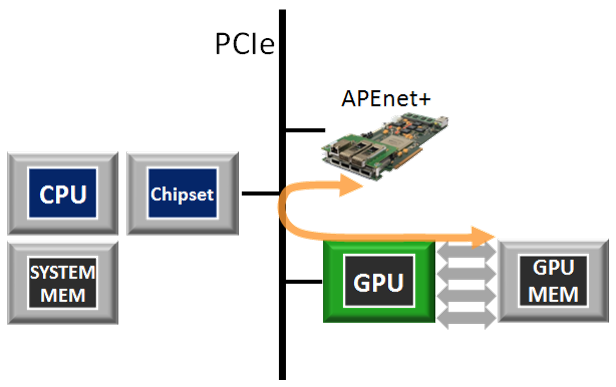
GPU I/O accelerator
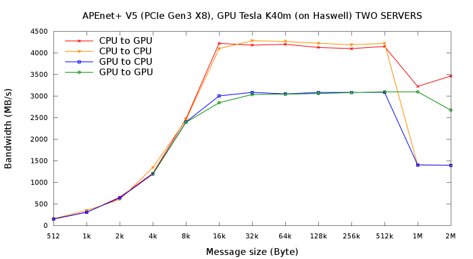
APEnet+ has been the first-of-its-kind device to implement an RDMA protocol to directly read/write data from/to Fermi and Kepler NVIDIA GPUs using NVIDIA peer-to-peer and GPUDirect RDMA protocols, obtaining real zero-copy GPU-to-GPU transfers over the network. This means that the APEnet+ network board can target GPU memory by ordinary RDMA semantics with no CPU involvement and dispensing entirely with intermediate copies . In this way, real zero-copy, inter-node GPU-to-host, host-to-GPU or GPU-to-GPU transfers can be achieved, with substantial reductions in latency.
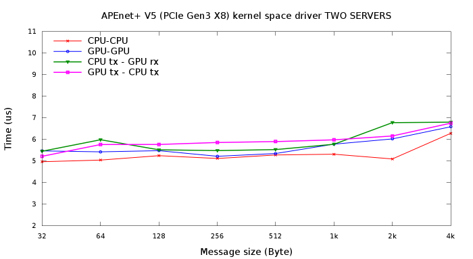
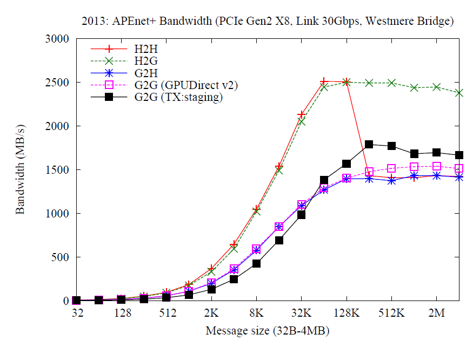
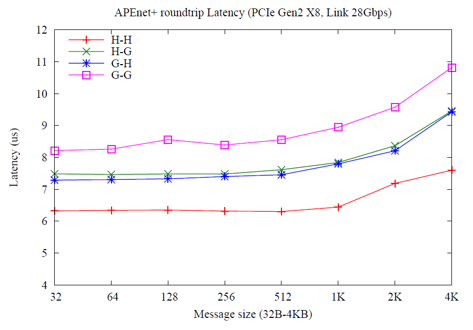
APEnet Performance